
How CPU Cache Works – Technology Explained

You’ve undoubtedly heard about CPU cache and know that a larger cache is better, but what exactly is it and why does it affect performance? Additionally, you may be wondering why the cache is so small, normally between 32 KB and 16 MB depending on the level of cache (which we will explain a bit further one) on a high end processor or less when system RAM is measured in gigabytes.
No matter how fast your system memory might be, with speeds in the tens of gigabytes per second and sometimes approaching 100 GB/s, it just isn’t fast enough to keep up with the processor. Going back several decades, before the days of the cache, system memory often ran faster than the speed of the processor. This was done so that the processor could request information from the memory and, while the CPU was processing the instruction, the video circuit could request information from the memory and output it to the screen.
This is an example of why the memory needs to be extremely fast. In order for this to happen today and with CPUs hitting 5 GHz, for the RAM to output twice per instruction it would need to run at 10 GHz (or more accurately, 10 billion transfers per second). That is still the case today when using integrated graphics that shares system memory.
With a slow CPU and very fast memory it is possible to get the memory running faster than the CPU (for example, a low end 3 GHz CPU bundled with DDR4-4800), but one thing that won’t change is the time it takes to get the data from the memory to the processor. This latency is partially due to how the memory is addressed and partially due to how long it physically takes the signal to travel from the source to the destination.
If we break it down to show why a low latency is vital, let’s assume that in one case we can send one byte (8 bits) of information at a time and the time taken for addressing that byte and transferring it is one second. In the second case, we can send one bit of information at a time and the time taken for the transfer is 125ms, or 1/8 of a second.
In both cases we can transfer at a speed of one byte per second, but if we only need to transfer a single bit the first scenario will still take a full second while the second will take 1/8 of a second. As processors only deal with extremely small amounts of information at a time, it isn’t necessarily just the raw throughput that is important but the latency as well. The latency of system memory is normally around 30 to 80 nanoseconds, while cache can be fractions of a nanosecond.
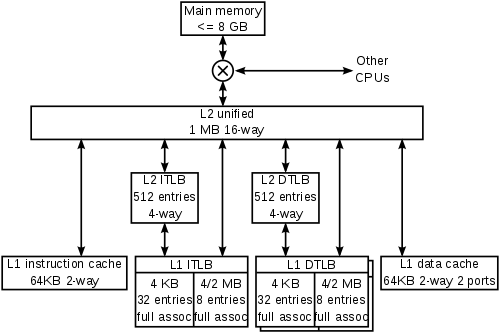

Cache hierarchy of an AMD Athlon64 processor
When memory becomes the bottleneck, increasing the speed of the CPU will have absolutely no effect on performance as you still need to wait for the memory. If your memory is only fast enough to saturate a 2 GHz processor but you’re running a 4 GHz processor, the processor will spend half of its time waiting for the memory and effectively perform at the speed of a 2 GHz processor.
While it is possible to build memory that performs at the same speed as (or even faster than) the processor, it takes up several orders of magnitude more space on the silicon and is therefore far more expensive to manufacture. Once again though, you would be left with the latency of the signal physically reaching the processor.
This is where the cache comes in. The cache overcomes the speed issue by being the type of fast memory that takes up more space, and the latency issue by being integrated into the processor’s die. Some older CPUs had the cache on a separate die within the CPU package or even on a separate card on the motherboard, but being on a separate die meant that there were higher latencies. These days all caches are integrated into the processor’s die.
To further understand the advantage of a cache of any type, your web browser also has a cache which is easier to explain. When you initially request a page, the entire contents of the page have to be fetched from the web server which is limited by the speed of the server and, most often to a much larger extent, the speed of your internet connection.
Once the page has been fully downloaded, a lot of the static content such as images are stored in a temporary location on your hard drive or SSD. When you refresh that page, the dynamic content (which might include the text) gets fetched again while the static content is read from your drive.
Assuming you have a high speed internet connection, such as a 100 Mbit/s line (keep in mind that’s megabits per second, not megabytes per second) and an SSD capable of 300 MB/s, the SSD is still capable of 24 times the speed of your internet connection. Add to this a latency of up to several hundred milliseconds for the connection depending on the physical location of the web server as opposed to far less than a millisecond for your SSD and you can see that the cache is significantly faster than redownloading everything.
Coming back to the CPU’s cache, the CPU works in a very similar way with the main system memory being the web server and the cache being the local copy of the information stored by your web browser.
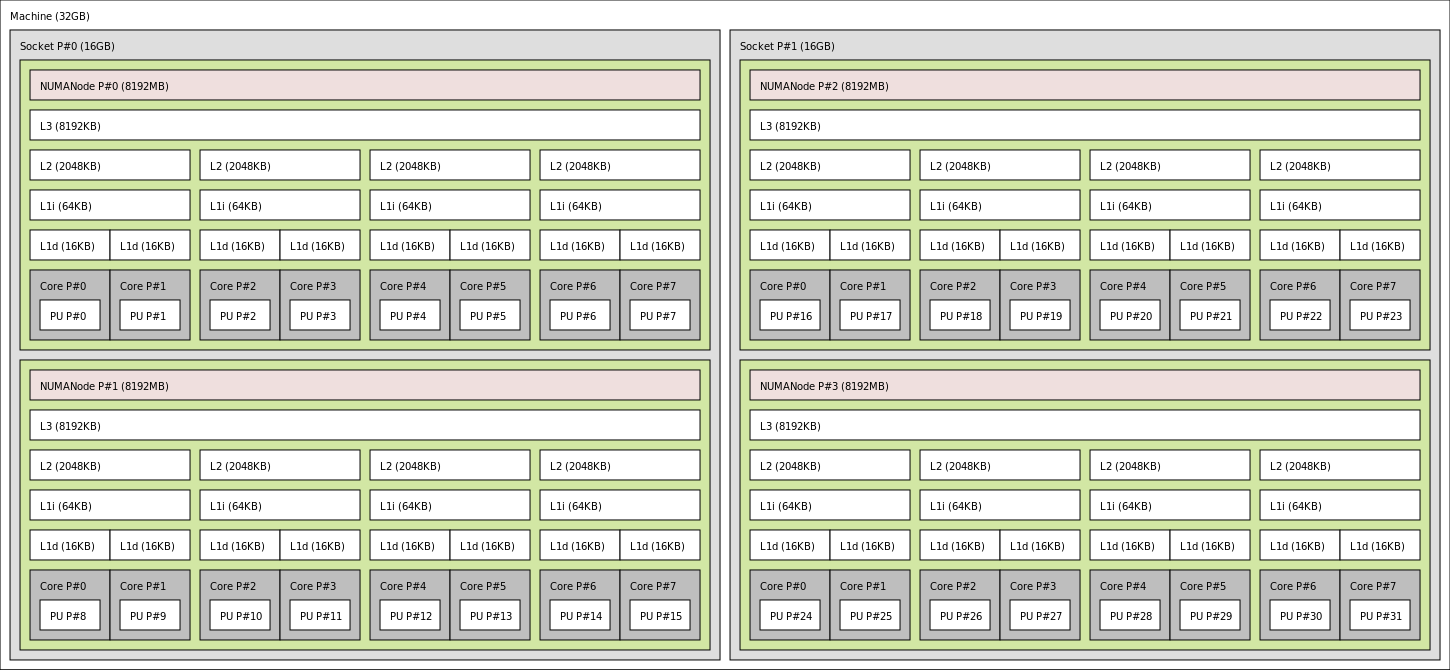
Cache hierarchy of an AMD Bulldozer processor
The CPU can also try to predict which information will need to be stored in the cache. Looking at the bit of information being requested, the CPU can figure out that if it’s requesting that particular bit there’s a good chance that it will request the following bit after that, and so on. By doing so it can request what’s called a cache line in one go, which might be 128 bytes. As we saw earlier with the two transfers that both run at one byte per second, it can be far quicker to send 128 bytes in one go than to request it on a bit-by-bit basis.
CPUs often process the same block of information in a loop – sometimes manipulating the information the same way over and over again, and other times manipulating it differently each time. Either way, it is often working with the same block of information for multiple instructions. For this reason we can get away with very small caches.
The cache is normally divided into several different “levels”, namely L1 to L3 and sometimes even L4. With each subsequently higher level number the cache is larger and slower than the previous level, with L1 being the smallest and fastest and L3 or L4 being the largest and slowest (but still faster than the main system memory).
The reason for this is if the data doesn’t fit in the very fast, small and expensive L1 cache (often around 64 KB per core – 32 KB for instructions and 32 KB for data), there is a good chance that the data will be found in the cheaper, slower and larger L2 cache (often around 256 KB per core), and an even higher chance that it will be in the L3 cache (which can be all the way up to a pooled 16 MB shared between all cores on a high end CPU.
If you’re a woodworker and want to build a cupboard, the first place you’ll look for wood might be your workshop (L1 cache). If you don’t find it there, you can look in your tool shed (L2 cache). If you still don’t find it there, you can check your attic (L3 cache). Each is larger and takes longer than the one preceding it, but they’re still faster than going down to your local hardware store (main system memory).







